


One of the most important steps of build apps that are highly dependent on data is to model your data the right way. In this post, I will be explaining some rules I follow on how I model data when building apps that are using MongoDB or NoSQL database.
Data Modelling
Data modeling is the process of taking raw data generated by a real-world scenario and then structure it to a logical data model we can easily and optically manipulate in a database.
Let say for example we want to design an online Bookstore system. Which will consist of entities such as inventory, authors, publishers, books, orders, customers, etc. Our objective with data modeling is to then structure this data logically, defining the relationships between the entities.
For me, data modeling is one of the most important steps that need a lot of attention, cause our entire application is highly dependent on it, and in most cases, it is not always direct. Now let us dive in
Identifying The Relationships Between Data
There are three main types of relationships. In this section, I will be using bookstore modeling as our real-life example.
One-to-One
In a one-to-one relationship, one record in a table is associated with one and only one record in another table. For example, in our bookstore application, A book can only have one name, Book ID.
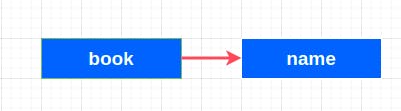
This a simple example of 1 to 1 relationship. This relationship is not that important, unlike the rest.
One-to-Many
In a one-to-many relationship, a document in a collection can be associated with one or more documents in another collection. For example, each book document can have many authors(collection of documents). This modeling is very important and one of the most common cases you will be coming across when designing a database. In MongoDB, we divide this further into 1-few, 1-Many, and 1-Ton. The major difference here is the amount of the many.
1-to-Few
A very good example of a 1 to few relationship in our bookstore application is books to authors relations relationship. If we think about it, you will realize a book can have many authors, but just a few(1-5). A book won't have thousands of authors so it is a typical 1 to few relationships.
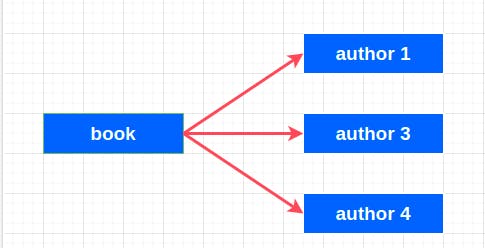
1-to-Many
In this relationship one book(document) can have hundreds/thousands of orders (collection) in our application. so this is not a one to few relationship.
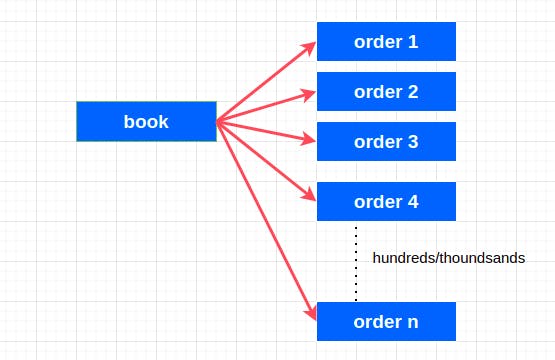
1-to-Ton
Let consider if we want to keep activities taking part in our applications, this log can grow to millions, it is almost heading to infinity. So it is safe to assume this is a 1 to ton relationship. This relationship is not common in most applications
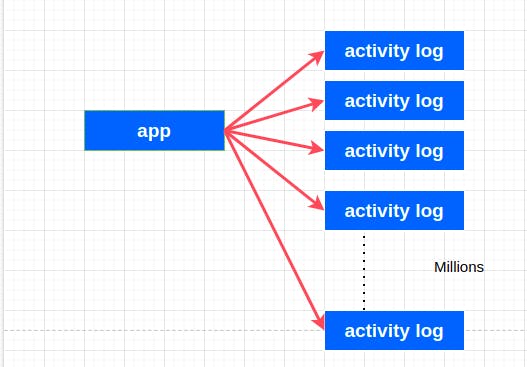
Many to Many
Here is the last type of relationship, where a book can have many publishers and at the same time a publisher can publish many books. This also works for books having many authors and an author has many books. So here the relationship goes both ways. So It is a many-to-many relationship.
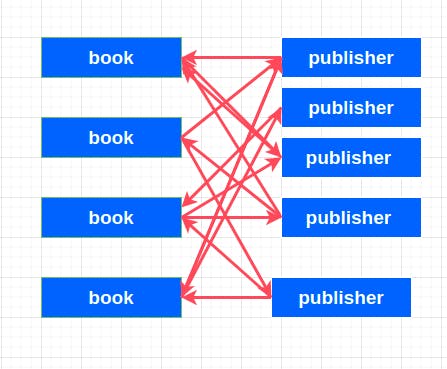
Referencing/Normalization VS Embedding/Denormalization
When we have two related documents or entities, we can either represent them in a reference/normalize form or embedded/denormalize form.
Reference/Normalize
In the reference form, we keep the two related documents nicely separated. Which is exactly what normalize means. So in the bookstore application, We will have one book document and one author document for each author. Looking at this, you begin to ask, how do we now connect them, well that is where the ID's come into play. So we use the author's ID to create references on the book document. The way we have effectively connected the authors to the book document.
In the book document we will have an array of IDs of all the authors so that when we request the data, we can populate our authors with the book document.
BOOK DOCUMENT
"_id" : ObjectID('233'),
"title": "7 Money Rules Of Life",
"type": "Inspirational",
"publication_year":"2021",
"authors": [
ObjectID('453'),
ObjectID('123'),
ObjectID('989'),
]
}
AUTHORS
{
"_id" : ObjectID('453'),
"first_name": "Jane",
"last_name": "Doe",
}
{
"_id" : ObjectID('123'),
"first_name": "Jane",
"last_name": "Doe",
}
{
"_id" : ObjectID('989'),
"first_name": "Jane",
"last_name": "Doe",
}
This is called child referencing because it is the book (parent) that contains the IDs of its children (authors). We also have the parent referencing where the child holds its parent ID. This method is a normal and good way in SQL databases.
Embed/Denormalize
We can embed/denormalize the data above simply by embedding the related document into the main document.
BOOK DOCUMENT
"_id" : ObjectID('233'),
"title": "7 Money Rules Of Life",
"type": "Inspirational",
"publication_year":"2021",
"authors": [
{
"_id" : ObjectID('453'),
"first_name": "Jane",
"last_name": "Doe",
}
{
"_id" : ObjectID('123'),
"first_name": "Jane",
"last_name": "Doe",
}
{
"_id" : ObjectID('989'),
"first_name": "Jane",
"last_name": "Doe",
}
]
}
The Pros and Cons Of Embedding and Referencing
For Embedded documents we have all the relevant data in a single document without the need for separate documents or referencing of IDs, the result is that our application will need to make fewer queries to fetch related documents, which implies an increase in our application performance. There is a downside to embedding, it is really difficult to query embedded documents on their own, so if that is a requirement in the application, I will advise separating them.
As for Reference, it is easier to query each document on its own and the trade is that we will need two queries to get data from referenced documents. So for example, if we need to query the authors of a book, we will first need to query the book, then query the author document.
So when designing your database, this is the kind of stuff we need to keep in mind. book, we will first need to query the book, then query the author document.
So when designing your database, this is the kind of stuff we need to keep in mind.
When To Embed or Reference Related Documents
I learned this from a course, there are three criteria we can consider. ### Relationship type(How the data sets are related) 1-to-few: It is okay to embed the data in this relationship cause the data set is expected to be small.
1-to-Many You can either choose to embed or reference, I prefer referencing.
Mant-to-Many or 1-to-Ton: It is highly advice-able to reference in this situation, cause the datasets can become too large or even go beyond mongo's 16MB limit.
Data Access Patterns (How often the data is read and write)
You should embed when
- Data is mostly read
- Data does not change quickly
- Their is High read and write ratio
You should reference when
- Data is updated a lot cause you will need to query it
- Low read and write ratio
Data Closeness (A measure of how much the data is related)
If the data set belongs together a lot, for exam book and its authors, year of publication, and the likes, then we should embed. If we frequently query both databases on their own, for example, book and their orders, It is better to reference them.
Types Of Referencing
Child Referencing
Let assume we have chosen to normalize our data set, which is when we will only need to reference.
1. Child Referencing
In this reference type, we keep the parent ID only in the child document. So taking our app, for example, A book can have many orders, so each order document will hold the ID of the book. So this way the child will always know its parent and the parent does not know about the child. In this case, we implement this in 1 to many and 1 to ton relationships.
2. Parent Referencing
In this reference type, we keep the parent ID only in the child document. So taking our app, for example, A book can have many orders, so each order document will hold the ID of the book. So this way the child will always know its parent and the parent does not know about the child. In this case, we implement this in 1 to many and 1 to ton relationships.
3. Two Way Referencing This mode of reference is used for many to many relationships, as I said earlier an author can have many books and, also possible for a book to have many authors. So what we do is a combination of our Child and Parent referencing. Each book will have an array of its authors and each author will also contain the id of their books.
That is the end of this post, I hope I have been able to help you understand data modeling, kindly drop an emoji or a comment for corrections...